
LEI 데이터
GLEIF 데이터 품질 관리
데이터 품질에는 사전 예방적 조치가 필요
사전 예방적 관리
LEI 발급 기관을 지원하기 위해 GLEIF는 적절한 필수 프로세스를 기술 인터페이스와 함께 제공하여 LEI 발급자가 LEI 및 관련 기준데이터의 데이터 품질을 사전에 평가할 수 있도록 하고 있습니다. 여기에는 전용 항목 중복 점검이 포함됩니다. LEI 기록은 자동화된 웹 서비스 API 데이터 거버넌스 사전 점검 및 중복 점검을 사용하여 한 번에 하나씩 점검해야 합니다.
데이터 거버넌스 사전 점검

LEI 발급자는 새로 발급 및 갱신되는 모든 LEI 기록을 글로벌 저장소에 업로드하기 전에 GLEIF의 사전 점검 기능으로 전송할 의무가 있습니다. 사전 점검 기능은 이미 게시된 LEI 기록에서도 실시되는 데이터 품질 점검을 동일하게 적용합니다. 사전 점검 결과에 따라 LEI 발급자는 잠재적 데이터 품질 문제가 공개 데이터 풀에 유입되기 전에 이러한 불일치를 해결할 수 있습니다. 확인 결과 외에도 요청자에게 설명이 제공되므로 보고된 문제를 집중적이고 신속하게 해결할 수 있습니다.
LEI 발급 기관은 이 기능을 의무적으로 사용함으로써 지속적인 개선 프로세스를 지원하여 글로벌 LEI 시스템에서 품질 기대치를 높이고 데이터 성숙도를 향상할 수 있습니다.
중복 점검
데이터 기록 중복을 방지하기 위해 새로 요청된 LEI 코드 및 해당 기준데이터는 글로벌 LEI 저장소의 다른 모든 기록 및 다른 LEI 발급자가 중복 점검 기능에 제출했지만 아직 발급되지 않은 LEI 기록과 비교됩니다. 따라서 두 곳의 개별 LEI 발급자에서 동일한 법인과 접촉한 경우에도 LEI 발급자가 잠재적 중복을 식별하고 고객과 조정하거나 서로 조정할 수 있습니다. 궁극적으로 이 절차는 시스템에서 중복 등록을 방지합니다.
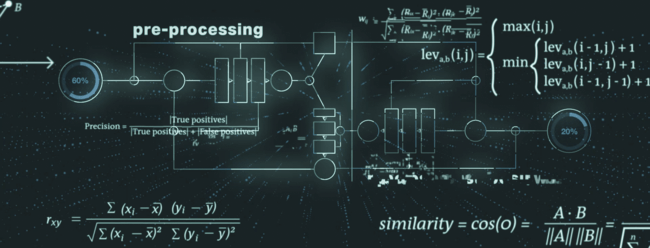
중복 식별 프로세스는 LEI 기록의 여러 데이터 요소를 고려하며 사전 처리, 코어 알고리즘 및 사후 처리로 구분할 수 있습니다.
사전 처리에서는 데이터가 예를 들어 소위 취약한 토큰을 식별하고 처리하는 등의 후속 단계를 위해 준비됩니다. 취약한 토큰의 일반적인 예는 법인명의 일부일 수 있는 법인의 법인 서식입니다. 그러면 법인 서식을 정규화하고 조화시켜 이후 프로세스 단계에서 최상의 결과를 얻을 수 있습니다.
중복 점검 기능의 코어 엔진은 퍼지 문자열 일치(예: Levenshtein 거리, 코사인 유사도, Monge-Elkan 거리)를 위한 최첨단 알고리즘을 결합한 고유성 및 배제성 점검으로 구성됩니다.
사후 처리 단계에서는 중복 점검 기능이 2차 데이터 요소(예: 법적 관할권, 법인 범주)에 대한 추가 점검 및 특별 처리를 기반으로 오탐지를 줄입니다.
관련 파일 다운로드
PDF 다운로드: 중복 점검 사전 v1.2 (Check for Duplicates Dictionary v1.2)