
Dati associati ai LEI
Gestione della qualità dei dati in seno alla GLEIF
La qualità dei dati richiede interventi proattivi
Gestione proattiva
Per supportare gli emittenti di codici LEI, la GLEIF fornisce processi adeguati e obbligatori e un'interfaccia tecnica per consentire di valutare proattivamente la qualità dei dati associati a un codice LEI e dei rispettivi dati di riferimento. Ciò include un controllo dedicato per verificare la presenza di voci duplicate. Le registrazioni di codici LEI devono essere verificate singolarmente tramite le API del servizio Web automatizzato, ovvero Verifica preventiva di governance dei dati e Verifica di duplicati.
Verifica preventiva di governance dei dati

Gli emittenti di codici LEI sono obbligati a inviare tutte le nuove registrazioni di codici LEI emesse e aggiornate al sistema di verifica preventiva della GLEIF prima di caricarli nell'archivio globale. Il sistema applica le stesse verifiche sulla qualità dei dati eseguite anche ogni giorno per le registrazioni dei codici LEI già pubblicati. In base ai risultati della verifica preventiva, gli emittenti di codici LEI possono risolvere potenziali problemi di qualità dei dati prima che tali lacune raggiungano il pool di dati pubblici. Oltre al risultato della verifica, il richiedente riceve anche una spiegazione, che consente più facilmente di applicare una soluzione mirata e rapida al problema riscontrato.
L'uso obbligatorio del sistema da parte degli emittenti di codici LEI è volto a sostenere il miglioramento continuo del processo, innalzando gli standard di qualità e incrementando il livello di maturità dei dati nel Sistema globale di codici LEI.
Verifica di duplicati
Per evitare la duplicazione di registrazioni di dati, i codici LEI richiesti e i rispettivi dati di riferimento vengono confrontati con tutte le altre registrazioni nell'archivio globale di codici LEI, nonché con le registrazioni di codici LEI inviati al sistema di verifica di duplicati da altri emittenti di codici LEI, ma non ancora emessi. Di conseguenza, anche se due diversi emittenti di codici LEI sono stati contattati dalla stessa persona giuridica, gli emittenti di codici LEI identificheranno i potenziali duplicati e potranno coordinarsi tra loro e con i propri clienti. In definitiva, questa procedura evita l'introduzione di duplicati nel sistema.
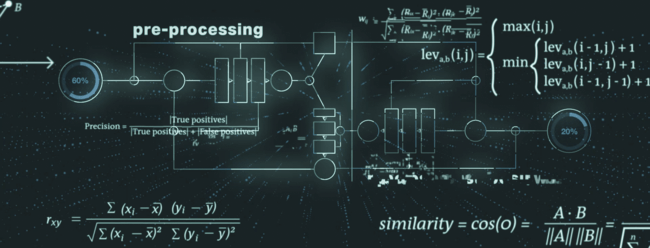
Il processo di identificazione dei duplicati prende in considerazione vari elementi dei dati della registrazione di codici LEI e può essere suddiviso in pre-elaborazione, algoritmo chiave e post-elaborazione.
Nella fase di pre-elaborazione, i dati vengono preparati per le fasi successive, ad esempio vengono identificati e gestiti i cosiddetti "token deboli". Un tipico esempio di token debole è la forma giuridica della persona giuridica, che può far parte del nome della persona giuridica specifica. Le forme giuridiche possono quindi essere normalizzate e armonizzate per garantire i risultati migliori possibili nelle fasi di elaborazione successive.
Il meccanismo chiave del sistema Verifica di duplicati è costituito da un controllo di univocità ed esclusività, che combina algoritmi all'avanguardia per trovare corrispondenze tra stringhe simili (ad esempio distanza di Levenshtein, similarità del coseno, distanza di Monge-Elkan).
Nella fase di post-elaborazione, il sistema Verifica di duplicati riduce il numero di falsi positivi in base a ulteriori controlli e al trattamento speciale di elementi secondari dei dati (ad esempio giurisdizione legale, categoria dell'entità).
File associati da scaricare
Scarica come PDF: Dizionario del sistema Verifica di duplicati v1.2 (Check for Duplicates Dictionary v1.2)