
Data LEI
Manajemen Kualitas Data GLEIF
Kualitas data memerlukan tindakan proaktif
Manajemen Proaktif
Untuk mendukung organisasi penerbit LEI, GLEIF menyediakan proses yang sesuai dan wajib bersama antarmuka teknis untuk memungkinkan penerbit LEI menilai kualitas data LEI dan data rujukan terkait secara proaktif. Proses ini meliputi pemeriksaan khusus untuk entri duplikat. Catatan LEI harus diperiksa satu per satu menggunakan API layanan web otomatis: Pra-Pemeriksaan Tata Kelola Data dan Pemeriksaan Duplikat.
Pra-Pemeriksaan Tata Kelola Data

Penerbit LEI wajib mengirimkan semua catatan LEI yang baru diterbitkan dan diperbarui ke fasilitas Pra-Pemeriksaan GLEIF sebelum mengunggahnya ke repositori global. Fasilitas Pra-Pemeriksaan menerapkan Pemeriksaan Kualitas Data yang juga dilakukan setiap hari untuk Catatan LEI yang sudah diterbitkan. Berdasarkan hasil Pra-Pemeriksaan, Penerbit LEI dapat memulihkan potensi masalah kualitas data sebelum inkonsistensi ini memasuki kumpulan data publik. Selain hasil pemeriksaan, pemohon juga menerima penjelasan, yang memfasilitasi remediasi terfokus dan cepat dari masalah yang dilaporkan.
Penggunaan fasilitas secara wajib oleh organisasi penerbit LEI mendukung proses peningkatan berkelanjutan, meningkatkan standar kualitas, dan meningkatkan kematangan data dalam Sistem LEI Global.
Pemeriksaan Duplikat
Untuk mencegah duplikasi catatan data, kode LEI yang baru diminta serta data rujukan terkait akan dibandingkan dengan semua catatan lain di Repositori LEI Global serta dengan catatan LEI yang telah diserahkan ke fasilitas Pemeriksaan Duplikat oleh penerbit LEI lain, tetapi belum dikeluarkan. Oleh karena itu, meskipun dua Penerbit LEI yang terpisah telah didatangi oleh badan hukum yang sama, Penerbit LEI akan mengidentifikasi kemungkinan duplikat dan dapat berkoordinasi dengan klien mereka serta dengan penerbit lain. Pada akhirnya, prosedur ini mencegah masuknya item duplikat ke dalam sistem.
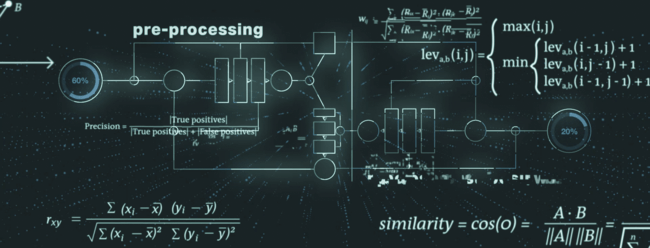
Proses identifikasi duplikat mempertimbangkan beberapa elemen data dari catatan LEI dan dapat dibagi menjadi pra-pemrosesan, algoritme inti, dan pasca-pemrosesan.
Selama pra-pemrosesan, data disiapkan untuk langkah-langkah berikutnya, misalnya token lemah diidentifikasi dan ditangani. Contoh tipikal untuk token yang lemah adalah bentuk hukum badan hukum yang dapat menjadi bagian dari nama badan hukum. Bentuk-bentuk hukum tersebut kemudian dapat dinormalisasi dan diselaraskan untuk memastikan hasil terbaik dalam tahapan proses berikut.
Pemrosesan inti dari fasilitas Pemeriksaan Duplikat terdiri dari pemeriksaan keunikan dan eksklusivitas, menggabungkan algoritma canggih untuk pencocokan string fuzzy (misalnya, jarak Levenshtein, kesamaan Cosinus, jarak Monge-Elkan).
Pada langkah pasca-pemrosesan, fasilitas Pemeriksaan Duplikat mengurangi jumlah positif palsu berdasarkan pemeriksaan tambahan dan perlakuan khusus terhadap elemen data sekunder (misalnya, yurisdiksi hukum, kategori entitas).
File Relevan untuk Diunduh
Unduh sebagai PDF: Kamus Pemeriksaan Duplikat v1.2 (Check for Duplicates Dictionary v1.2)