
Datos del IPJ
Gestión de la Calidad de los Datos de la GLEIF
La calidad de los datos requiere acciones proactivas
Gestión proactiva
A fin de dar soporte a las organizaciones emisoras de IPJ, la GLEIF proporciona el procedimiento apropiado y obligatorio junto con una interfaz técnica para que los emisores de IPJ puedan evaluar de forma proactiva la calidad de los datos de un IPJ y los datos de referencia relacionados. Esto incluye una comprobación de duplicados específica. Los registros de IPJ deben comprobarse de uno en uno utilizando las API de servicios web automatizados: Comprobación previa de la gobernanza de los datos y Comprobación de duplicados.
Comprobación previa de la gobernanza de los datos

Los emisores de IPJ están obligados a enviar todos los registros de IPJ recién emitidos y actualizados al servicio de comprobación previa de la GLEIF antes de cargarlos en el depósito global. El servicio de comprobación previa aplica las mismas comprobaciones de la calidad de los datos que también se llevan a cabo diariamente para los registros de IPJ ya publicados. Según los resultados de la comprobación previa, los emisores de IPJ pueden corregir los posibles problemas de calidad de los datos antes de que estas incoherencias entren en el conjunto de datos públicos. Además del resultado de la comprobación, el solicitante también recibe una explicación, lo que facilita una solución específica y rápida del problema notificado.
El uso obligatorio del servicio por parte de las organizaciones emisoras de IPJ apoya el proceso de mejora continua, elevando el nivel de calidad y aumentando el nivel de madurez de los datos en el Sistema Global del IPJ.
Comprobación de duplicados
Para evitar registros de datos duplicados, los códigos de IPJ recién solicitados y los datos de referencia correspondientes se comparan con todos los demás registros del Depósito Global del IPJ, así como con los registros de IPJ que se han enviados al servicio de comprobación de duplicados por otros emisores de IPJ, pero que aún no se han emitido. Por lo tanto, incluso si dos emisores de IPJ distintos han sido contactados por la misma persona jurídica, los emisores de IPJ identificarán posibles duplicados y podrán coordinarse con sus clientes y entre sí. En última instancia, este procedimiento evita la introducción de duplicados en el sistema.
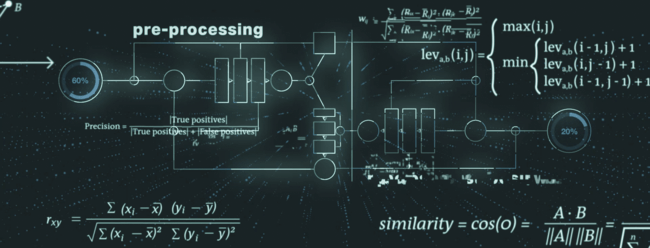
El proceso de identificación de duplicados tiene en cuenta varios elementos de datos del registro del IPJ y puede dividirse en preprocesamiento, algoritmo central y posprocesamiento.
Durante el preprocesamiento, los datos se preparan para los siguientes pasos; por ejemplo, se identifican los llamados tokens débiles y se les presta atención. Un ejemplo típico de token débil es la forma jurídica de la persona jurídica, que puede ser parte del nombre de la persona jurídica. A continuación, las formas jurídicas podrían normalizarse y armonizarse para garantizar los mejores resultados posibles en las siguientes fases del proceso.
El motor principal del servicio de comprobación de duplicados consiste en una comprobación de singularidad y exclusividad, que combina algoritmos de última generación para la comparación de cadenas difusas (por ejemplo, distancia Levenshtein, similitud coseno, distancia Monge-Elkan).
En la fase de posprocesamiento, el servicio de comprobación de duplicados reduce el número de falsos positivos mediante comprobaciones adicionales y un tratamiento especial de los elementos de datos secundarios (por ejemplo, la jurisdicción legal o la categoría de la persona).
Archivos relevantes para descargar
Descargar como PDF: Diccionario de Comprobación de duplicados v1.2 (Check for Duplicates Dictionary v1.2)